Updating a Deployment
With Cloudify, you can update a deployment, which serves multiple purposes:
- Changing the deployment topology: for example, adding a new type of database to an existing deployment of webservers and databases.
- Changing the settings of existing nodes: for example, resizing a volume, or changing the size of a VM instance.
- Updating the real state of the provisioned resources to match the blueprint. For example: after manually resizing a volume by using a cloud provider’s console, run update to bring the volume back to the state described in the blueprint.
Describing a Deployment Update
A deployment update consists of:
- An application blueprint. If a new blueprint is not provided, the current blueprint is used, and the overall deployment topology is kept unchanged.
- New deployment inputs. If new inputs are not provided, existing inputs are used.
- Additional parameters for toggling parts of the update flow on and off.
The application blueprint is a yaml blueprint file, just as any with any other blueprint in Cloudify (note that the blueprint represents the desired state of the deployment after the update). Using the example described in the introduction, the updated application blueprint would include a new database type, some new node templates of the new database type, and some new relationships that represent how these new nodes connect to the existing architecture.
Deployment update steps
When an update is executed, the Cloudify Manager computes the differences between the old blueprint & inputs, and the new blueprint & inputs - based on those differences, the deployment update steps are generated.
A step is a logical concept that represents a single change in a deployment update. There are three different types of steps, add, remove, and modify. The scope of a step is determined by its most top-level change. For example, if a node is added that also contains a new relationship, this is an ‘add node’ step, not an ‘add relationship’ step. Similarly, if a node’s property is modified, it is not a ‘modify node’ step, but a ‘modify property’ step. A list of all possible steps is located here.
Detecting configuration drift
In addition to applying the changes based on a new blueprint, the Cloudify Manager can also:
- check the status of each node instance in the deployment
- if necessary, heal the failing node instances
- check the configuration drift of each node instance - find the differences between the node configuration as described in the blueprint, and the real state of the provisioned resources
- if necessary, update the provisioned resources to match the blueprint.
This status and drift checking is based on the operations defined by each node, usually in a plugin.
Deployment Update Flow
Updating a deployment is a multi-stage process. The high-level overview of the workflow is:
- The differences between the old and the new blueprint are computed.
- The steps composing the deployment update are extracted.
- The Cloudify Manager data storage is updated with:
- the updated deployment attributes (e.g. labels)
- the newly-created node instances
- the updated node properties
- the updated node instance relationships
- The
uninstalloperations are executed on each deleted node instance. - The
installoperations are executed on each added node instance. - The
check_status(andhealif necessary) operations are executed on all started node instances in the deployment. - The
check_drift(andupdateif necessary) operations are executed on all started and healthy node instances in the deployment. - The
reinstalloperations are executed on each changed node instance. - The deleted nodes and node-instances are removed from the Cloudify Manager data storage.
For a more in-depth description of these steps, see the workflow documentation
For notes about implementing the check_drift and update operations, see implementing drift check
Using Cloudify Management Console to Update a Deployment
To update a deployment from the Cloudify Management Console go to Services page, select Deployment from the left pane, then click on the Deployment Actions button and select Update option.
You will then see Deployment Update modal window:
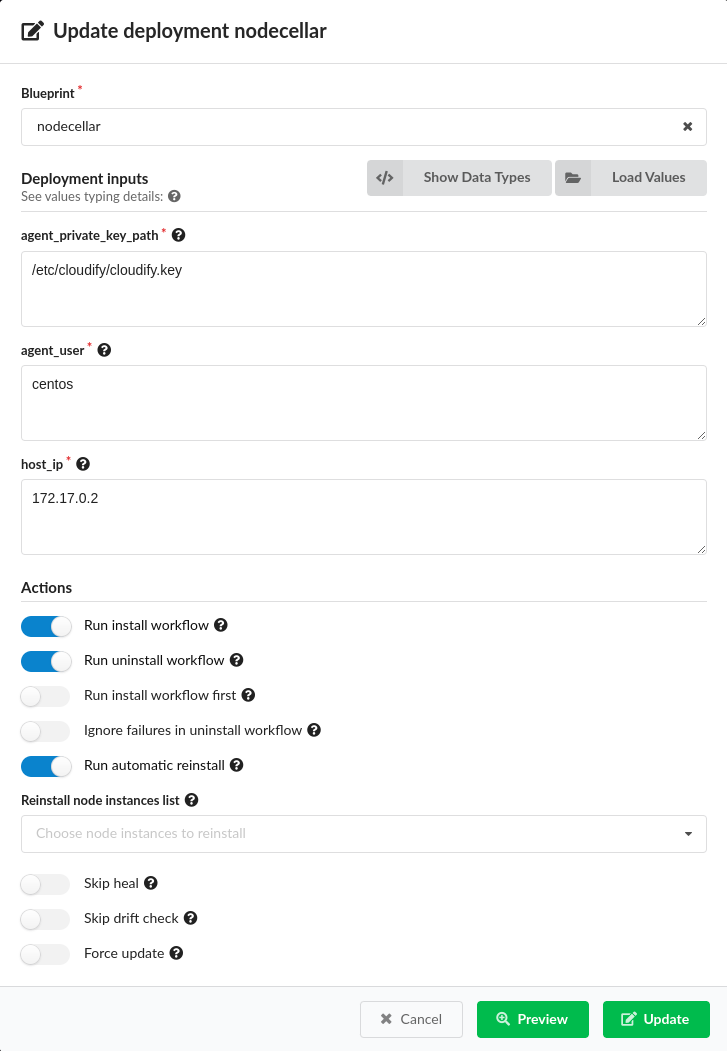
In that window you can:
- set new Blueprint for the deployment,
- set new Inputs for the deployment either automatically using inputs YAML file or providing each input value directly to the form,
- set specific Actions to be taken upon deployment update like enabling/disabling Install/Uninstall workflows on specific node instances.
You can now choose if you want to do the update (Update button) or just preview (Preview button) what is going to be changed.
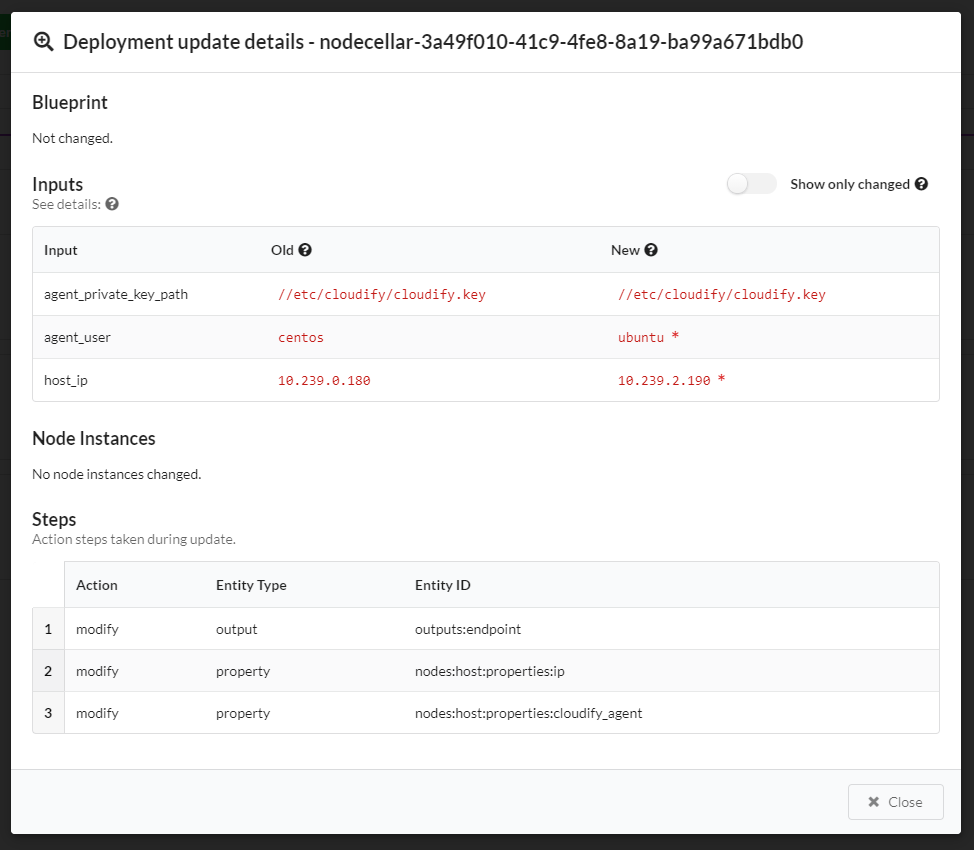
In Preview mode you can see the following information:
- blueprint changes,
- inputs changes,
- node instance changes,
- actions steps to be taken.
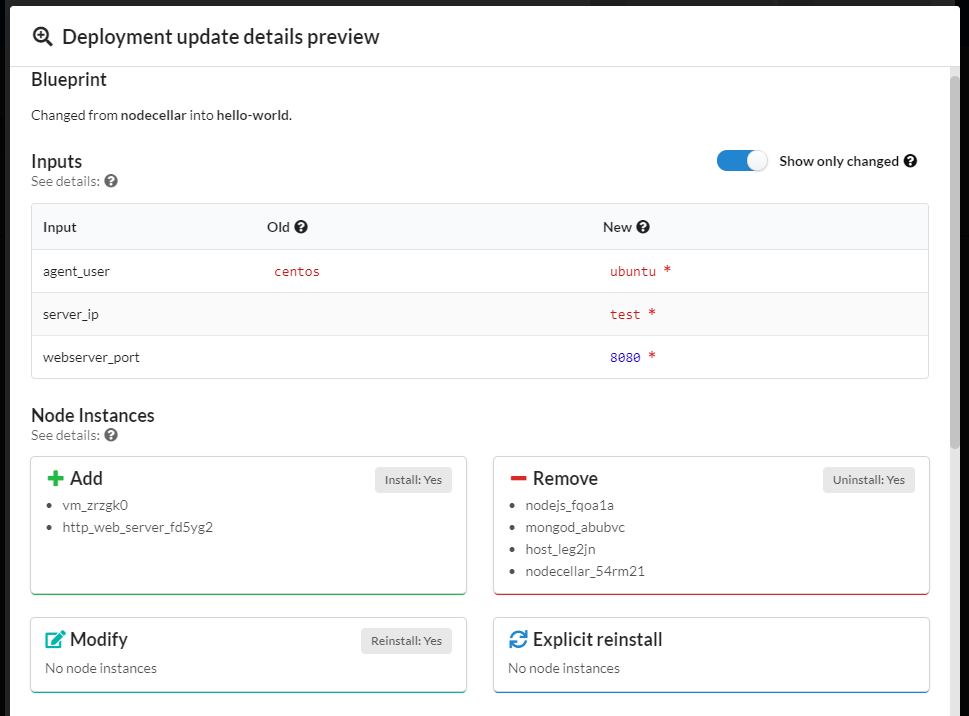
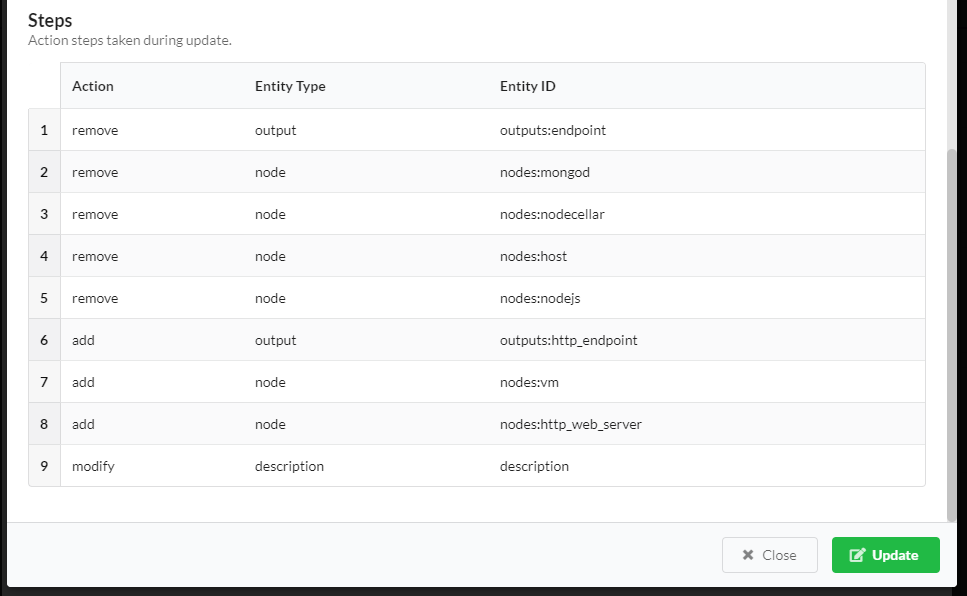
If you want to get the same information about update performed in the past:
-
Go to History tab on the specific deployment page and scroll to Executions widget
-
Click on the menu icon (
 ) on relevant execution and select Show
Update Details option (only available for executions associated with deployment update)
) on relevant execution and select Show
Update Details option (only available for executions associated with deployment update) -
See changes in Deployment Update Details modal window:
Using the CLI to Update a Deployment
You can update your deployment using the CLI. Updating a deployment via the CLI is similar to creating a deployment, besides the fact that you supply an argument of the existing deployment’s id. You must also supply either a blueprint id or new inputs (or both) for the deployment update to use. The deployment’s blueprint and inputs will be updated in the data model.
-
Run the following command to update a deployment (must supply either blueprint id, or new inputs, or both):
cfy deployments update ID_OF_DEPLOYMENT_TO_UPDATE -b BLUEPRINT_ID -i UPDATED_INPUTS -
Run the following command to get data about a deployment update:
cfy deployments get-update DEPLOYMENT_UPDATE_ID -
Run the following command to list deployment updates (if the deployment id parameter is supplied - list updates for a specific deployment, otherwise - list updates for all deployments):
cfy deployments history [-d DEPLOYMENT_ID]
See more of the CLI usage in the CLI deployments documentation.
Skipping parts of the update procedure
You can skip parts of the Deployment Update procedure using flags. By default, all phases are enabled. The flags can be combined as needed.
The relevant CLI flags are:
- To run an update without actually doing any changes to the blueprint, but still run the
check_driftandupdateoperations, use the--drift-onlyflag:cfy deployments update ID_OF_DEPLOYMENT_TO_UPDATE --drift-only - To skip the execution entirely, and exit immediately after generating steps, use the
--previewflag:cfy deployments update ID_OF_DEPLOYMENT_TO_UPDATE -b BLUEPRINT_ID --preview - To skip the
installexecution, use the--skip-installflag:cfy deployments update ID_OF_DEPLOYMENT_TO_UPDATE -b BLUEPRINT_ID --skip-installAdded nodes will not be installed, added relationships will not be established.
- To skip the
uninstallexecution, use the--skip-uninstallflag:cfy deployments update ID_OF_DEPLOYMENT_TO_UPDATE -b BLUEPRINT_ID --skip-uninstallRemoved nodes will not be uninstalled, removed relationships will not be unlinked.
- To skip the
reinstallexecution, use the--skip-reinstallflag:cfy deployments update ID_OF_DEPLOYMENT_TO_UPDATE -b BLUEPRINT_ID --skip-reinstall - To skip the
check_statusandhealexecution, use the--skip-healflag:cfy deployments update ID_OF_DEPLOYMENT_TO_UPDATE -b BLUEPRINT_ID --skip-heal - To skip the
check_driftexecution, use the--skip-drift-checkflag:cfy deployments update ID_OF_DEPLOYMENT_TO_UPDATE -b BLUEPRINT_ID --skip-drift-check
Ignoring failures while uninstalling nodes
When running uninstall (including uninstall as part or a reinstall) there are 2 possible ways of handling a recoverable error in a task:
-
Like any other workflow, retry the task until it succeeds (and then move on to the next task), or until reached the maximum retries number (and then fail the execution). This is the default behavior.
-
Ignore the failure and simply move on to the next task (this methods assumes that a failure in uninstall workflow is not critical and less likely to have negative affect). This behavior is used when the parameter
ignore_failureis set totrue. -
To set ignore_failure to be true (by passing the –ignore-failure flag), run the following command:
cfy deployments update ID_OF_DEPLOYMENT_TO_UPDATE -b BLUEPRINT_ID --ignore-failure
In this case, all failures in tasks that are part of uninstalling nodes will be ignored, and the update will continue as planned.
This can be used in different situations, for example:
- Some of the nodes that has to be uninstalled/reinstalled are damaged and their uninstallation may not work perfectly.
- The nodes that are being uninstalled have properties that were modified in this update and are being used at the nodes uninstall workflow (but not necessarily critical to its success) and the fact that they were modified may fail some tasks.
- This update is a roll-back after a failing update, so it is likely that some of its tasks will fail (uninstallation of nodes that were not installed properly in the original update).
Recovering from a Failed Update
If a deployment update workflow fails during its execution, you would probably want to perform a “rollback” in order to recover. A common solution is to update the deployment with a blueprint which represents the previous (state of the) deployment. In order to do that make sure there is no running update workflow for your deployment. Look for the latest update workflow on the list:
cfy executions list -d DEPLOYMENT_ID
You will find more information on cancelling workflow executions on a dedicated page of this documentation.
The next (and the final) step of recovery opration is performing a deployment update with the
original blueprint. The --reevaluate-active-statuses flag will help to make sure that the status
of previous deployment update is aligned with the status of relevant execution.
-
To force a deployment update execution, run the following command:
cfy deployments update ID_OF_DEPLOYMENT_TO_UPDATE -b ID_OF_THE_ORIGINAL_BLUEPRINT_BEFORE_THE_FIRST_UPDATE --reevaluate-active-statuses -
As mentioned before, in this situation it makes sense to also use the
--ignore-failureflag, like this:cfy deployments update ID_OF_DEPLOYMENT_TO_UPDATE -b ID_OF_THE_ORIGINAL_BLUEPRINT_BEFORE_THE_FIRST_UPDATE --reevaluate-active-statuses --ignore-failure
Providing Inputs
You can provide new inputs while updating a deployment. You provide the inputs in the same manner as when creating a deployment, with the following important distinctions:
Overriding inputs
If you provide an input with the same name as an existing deployment input, it overrides its value. Other new inputs will be added to the data model as usual.
Example: Overriding inputs of existing nodes
Assume that you have the following node in your deployment, and that the port input has a value of 8080:
webserver:
# ...
properties:
port: {get_input: port}
Any new nodes (including new webserver nodes) that were added as a part of that deployment update and use the port input, are assigned with the new port input value - 9090.
The overriden input will cause a modification in the webserver node (his port property was changed). This will trigger an automatic reinstallation of all the instances of the webserver node, so the updated port will take affect.
If the --skip-reinstall flag was passed, automatic reinstall will not be triggered, and although the input was overriden to 9090, the actual port on the existing server will remain 8080.
Automatically correcting old inputs’ types
In case you are trying to update a deployment but cannot because of an error similar to this one:
dsl_parser.exceptions.DSLParsingException: Property type validation failed in 'delay': the defined type is 'integer', yet it was assigned with the value '20'
please use the --auto-correct-types flag along with cfy deployments update. It’s purpose is to
automatically convert old inputs values’ types from string to integer, float or boolean,
based on the type of the input declared in a blueprint.
Implementing drift check
To avoid reinstalling instances when their properties have changed, implement the check_drift and update operations. Instances of nodes that implement those operations, will run them instead of being reinstalled.
The check_drift operation
The cloudify.interfaces.lifecycle.check_drift operation should examine the node properties, the instance runtime properties, and the actual state of the provisioned resource, and compute the differences.
The instance will be considered drifted if this operation returns a non-empty value (for example, a Python dict describing the differences).
The Cloudify Manager doesn’t inspect the returned value, so it can be any object. Plugin authors are advised to return a description of all the differences, so that the update operation can act upon them.
If check_drift returns an empty or false value, update operations will not run, and even in case of blueprint changes (e.g. if the node properties have changed), the instances will not be updated or reinstalled. Take care to always return a non-empty or true value if there are any changes to the instances.
Values are evaluated using Python bool() semantics; for example, the empty dict, the number 0, the empty string, the boolean False, or None, are all considered false.
If the check_drift operation is not implemented, the instances are only considered drifted if there are relevant blueprint changes (e.g. the node properties have changed).
The update operations
The update operations are:
cloudify.interfaces.lifecycle.updatecloudify.interfaces.lifecycle.update_configcloudify.interfaces.lifecycle.update_apply
Plugin authors can implement any, or all, of these operations. These three operations can be implemented in a way that mirrors the create, configure, and start operations.
In these operations, the value returned from check_drift can be accessed using ctx.instance.drift.
If none of these operations are implemented, the instance will be reinstalled in case of any drift.
check_drift and update example
In this example, consider a volume created on some cloud platform - to allow resizing that volume, implement the check_drift and update operations:
node_types:
type: cloudify.nodes.SomeHypotheticalCloud.Volume
properties:
size: 100MB
interfaces:
cloudify.interfaces.lifecycle:
check_drift: plugin.some_cloud.volumes.check_drift
update: plugin.some_cloud.volumes.update
def check_drift(ctx):
cloud_client = _make_cloud_client(ctx)
volume = cloud_client.volumes.get(ctx.instance.id)
# drift must be a COMPLETE description of drift - including ALL things that
# changed. If the result is empty, update will NOT run. In this example,
# the only property of the volume is size, so we only check the size.
drift = {}
actual_size = volume.size
requested_size = ctx.node.properties['size']
if actual_size != requested_size:
drift['size'] = {'actual': actual_size, 'requested': requested_size}
# if the actual size is equal to requested, return an empty dict - no drift
return drift
def update(ctx):
cloud_client = _make_cloud_client(ctx)
volume = cloud_client.volumes.get(ctx.instance.id)
drift = ctx.instance.drift
# in this example, if update runs, `size` will always be present, because
# that's the only thing that could have changed. In more complex types,
# there could be many more changed properties.
if 'size' in drift:
actual, requested = drift['size']['actual'], drift['size']['requested']
ctx.logger.info('Volume size should be %s, but is %s, resizing...',
requested, actual)
cloud_client.volumes.resize(volume.id, requested)
What Can be Updated as a Part of a Deployment Update
The following can be updated as part of a deployment update, subject to the limitations that were previously described in the Unsupported Changes section.
Nodes
You can add or remove nodes, including all their relationships, operations, an so on. Remember that adding or removing a node triggers the install/uninstall workflow in regard to that node.
Assume that the original deployment blueprint contains a node named node1. Then, in the deployment update blueprint, you decide to ‘rename’ that node, to node2. Now the deployment update blueprint’s node2 is identical to node1 in the original blueprint, except for its name. But in practice, there isn’t really a ‘renaming’ process. In this scenario, node1 is uninstalled and node2 is installed, meaning that node1 does not retain its state.
# original deployment blueprint
node_templates:
node1:
# ...
# deployment update blueprint
node_templates:
# node1 will be uninstalled. node2 will be installed
node2:
# ...
Relationships
With the exception of being added or removed as part of adding or removing a node, you can add or remove relationships independently. Adding a relationship triggers an execution of its establish operations (assuming a default install workflow). Similarly, removing a relationship triggers an execution of the unlink operations. You can also change a node’s relationship order. The operations of the added and removed relationships are executed according the order of the relationships in the deployment update blueprint.
# original deployment blueprint
node_templates:
node1:
relationships:
- type: cloudify.relationships.connected_to
target: node2
# deployment update blueprint
node_templates:
node1:
relationships:
- type: cloudify.relationships.connected_to
target: node3 # the previous relationship to node2 will be removed (unlinked), and a new relationship to node3 will be added (established)
Operations:
You can add, remove or modify node operations and relationship operations.
# original deployment blueprint
node_templates:
node1:
interfaces:
interface1:
operation1:
implementation:
plugin1.path.to.module.taskA
operation2:
implementation:
plugin2.path.to.module.taskA
relationships:
- # ...
source_interfaces:
interface1:
operation1:
implementation:
plugin1.path.to.module.taskB
plugins:
plugin1:
# ...
plugin2:
# ...
# deployment update blueprint
node_templates:
node1:
interfaces:
interface1:
operation1:
implementation: # modified operation1 (changed implementation)
plugin1.path.to.module.taskB
# removed operation2
operation3: # added operation 3
implementation:
plugin2.path.to.module.taskB
relationships:
- # ...
source_interfaces:
interface1:
operation1:
implementation: # modified operation1 (changed implementation to a different plugin)
plugin2.path.to.module.taskC
plugins:
plugin1:
# ...
plugin2:
# ...
Properties
You can add, remove, or modify properties. Note that overriding a default property value is treated as a property modification.
# original deployment blueprint
node_templates:
node1:
type: Cloudify.nodes.Compute
node2:
type: my_custom_node_type
properties:
prop1: value1
# deployment update blueprint
node_templates:
node1:
type: Cloudify.nodes.Compute
properties:
ip: 192.0.2.1 # modified the property by overriding its default (from types.yaml)
node2:
type: my_custom_node_type
properties:
# removed property prop1
prop2: value2 # added property prop2
Outputs
You can add, remove or modify outputs.
# original deployment blueprint
outputs:
output1:
value: {get_input: inputA}
output2:
# ...
# deployment update blueprint
outputs:
output1:
value: {get_input: inputB} # modified the value of output1
# removed output2
output3: # added output3
# ...
Workflows
You can add, remove or modify workflows.
# original deployment blueprint
workflows:
workflow1: plugin_name.module_name.task1
workflow2:
# ...
# deployment update blueprint
outputs:
workflow1:
value: plugin_name.module_name.task2 # modified the value of workflow1
# removed workflow2
workflow3: # added workflow3
# ...
Plugins
You can add, remove or modify plugins.
# original deployment blueprint
imports:
- plugin:plugin-name-1?version=1.0
- plugin:plugin-name-2?version=1.0
# deployment update blueprint
imports:
- plugin:plugin-name-1?version=2.0
- plugin:plugin-name-3?version=1.0
In this example, plugin-name-1 will be updated from version 1.0 to version 2.0, plugin-name-3 will be added to the deployment, and plugin-name-2 removed from it.
In cases of updating a plugin that was used to install nodes in the deployment (for example, Openstack plugin used to install Openstack nodes), the plugin update may trigger automatic reinstallation of those nodes. It can be avoided by using the --skip-reinstall flag.
It is possible to import plugins with no version specification at all. Then, the highest version of that plugin will be selected at deployment update time. Therefore, two deployments created (or updated) at different times can use different plugin versions (if a new version of the plugin was uploaded between creating those deployments). Also, if the version is not constrained, then any deployment update could lead to unintentionally upgrading the plugin to the newest version.
If you’d like to update the plugins for all the deployments of some specific blueprint, see the section below.
If you’d like to learn more about plugins version ranges, go here.
Plugins are installed on first use, so a deployment update is not necessarily going to install them up front. They will only be installed on the machine that attempts to use them, when needed.
Updating plugins for a collection of deployments
If you’d like to perform an update for all the deployment of some blueprint, and update only their plugins, you can perform a plugins update. You can find more information on the CLI command here.
Description:
You can add, remove or modify the description.
Adding a description:
# original deployment blueprint
# no description field
# deployment update blueprint
description: new_description # added description
Removing a description:
# original deployment blueprint
description: description_content
# deployment update blueprint
# removed the description
Modifying a description:
# original deployment blueprint
description: old_description
# deployment update blueprint
description: new_description
Unsupported Changes in a Deployment Update
If a deployment update blueprint contains changes that are not currently supported as a part of an update, the update is not executed, and a message indicating the unsupported changes will be displayed to the user. Following is a list of unsupported changes, together with some possible examples.
Node Type
You cannot change a node’s type.
# original deployment blueprint
node_templates:
node1:
type: my_type
# deployment update blueprint
node_templates:
node1:
type: my_updated_type # unsupported update - can't modify a node's type!
contained_in Relationship Target
You cannot change the target value of a cloudify.relationships.contained_in type relationship, or any type that derives from it.
# original deployment blueprint
node_templates:
node1:
relationships:
- type: cloudify.relationships.contained_in
target: node2
# deployment update blueprint
node_templates:
node1:
relationships:
- type: cloudify.relationships.contained_in
target: node3 # unsupported update - can't modify a contained_in relationship's target
Relationship Properties
You cannot change a relationship’s property, for example, connection_type.
# original deployment blueprint
node_templates:
node1:
relationships:
- # ...
properties:
connection_type: all_to_all
# deployment update blueprint
node_templates:
node1:
relationships:
- # ...
properties:
connection_type: all_to_one # unsupported update - can't modify a relationship's property
Groups, Policy Types and Policy Triggers
You cannot make changes in the top level fields groups, policy_types and policy_triggers as a part of a deployment update blueprint.