Relationships
relationships in Cloudify are DSL elements that establish dependencies between node templates, but also can be used to perform operations (i.e. execute code). Relationships are declared in a relationships section in a node template declaration at the same level as properties and interfaces, and are often defined in plugins. A node template can contain any number of relationship declarations, within certain constraints noted below. Each relationship declaration refers to two node templates in a blueprint: the source and the target. The source node is implicit; it is the node template that the relationship is declared in. The target is explicit, and refered to by node id. Example:
node1:
type: cloudify.nodes.Root
relationships:
# This relationship connects the "source" (node1) to the "target" (node2)
- type: cloudify.relationships.depends_on
target: node2
node2:
type: cloudify.nodes.Root
....
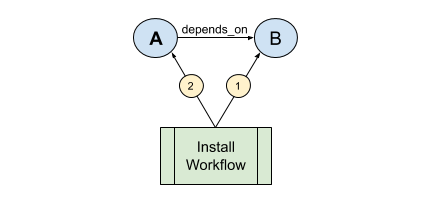
Relationships in Cloudify are explicit; a blueprint that contains no relationships will operate on all contained nodes simultaneously, regardless whether the node templates refer to each other via intrinsic functions. The fundamental relationship type in Cloudify is called cloudify.relationships.depends_on. It (and other relationships derived from it) is used by built-in workflows such as install for ordering of node instance evaluation, and in some cases executing code.
Relationships are declared in individual node templates, and have a type and a target. If node A declares a depends_on relationship to node B, this conveys a sense of order to the built-in workflows. In the case of the install workflow, it means ‘process node B before node A’. In the case of the uninstall workflow it means ‘process node A before node B’.
Declaration
node_templates:
node:
...
relationships:
- type: ""
target: ""
properties:
connection_type: ""
source_interfaces: {}
target_interfaces: {}
...
Schema
| Keyname | Required | Type | Description |
|---|---|---|---|
| type | yes | string | Either a newly-declared relationship type or one of the relationship types provided by default when importing the types.yaml file. |
| target | yes | string | The name of the node to which the current node is related. |
| connection_type | no | string | Valid values: all_to_all and all_to_one (See explanation below.) |
| source_interfaces | no | dict | A dictionary of interfaces. |
| target_interfaces | no | dict | A dictionary of interfaces. |
By default, nodes can be related using the relationship types described below. You may also [declare your own](#declaring-relationship-types) relationship types.
Fundamental Built-in Relationships
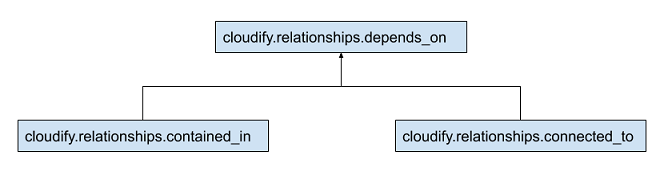
There are three fundamental relationships defined by Cloudify, which underlie all other relationship types, including those defined in plugins or blueprint authors. The base/root relationship type is cloudify.relationships.depends_on, which indicates processing order to the built-in workflows. All relationships, even custom relationships, must ultimately derive from the depends_on relationship. Derived from this relationship are cloudify.relationships.connected_to, and cloudify.relationships.contained_in.
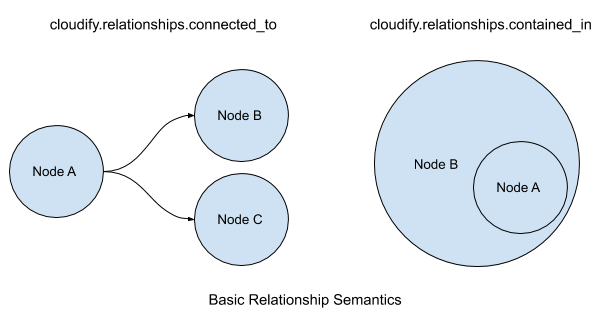
cloudify.relationships.contained_in indicates that the source node is “inside” the target node. Often this is used to indicate that a node representing a software package is to be placed on a node representing a compute instance (or instances). Each node template can only have a single contained_in relationship. This limitation is enforced universally by the DSL parser ( i.e. it isn’t a workflow specific quality ). If the relationship target is derived from cloudify.nodes.Compute, the built in workflows will understand this to mean that the source node instance is to be remotely installed on target instance, which will trigger the installation of an agent (unless explicitly disabled).
cloudify relationships.connected_to is treated similarly to the base depends_on relationship. Any node template can define any number of connected_to relationships, and the only effect will be node instance processing order. There is, however, a property that affects the processing when multiple node instances are involved (see the specific connected_to section below. Both connected_to and contained_in relationships can exist on the same node template.
All other relationships, whether built in or custom, inherit their semantics from the basic types. Additional functionality may be added by specific TOSCA types, but the basic functionality is unchanged.
Relationship Reference
The cloudify.relationships.depends_on Relationship Type
The root type of all relationship types. Defines the order of instantiation (or destruction) between nodes in a blueprint. The relationship target is instantiated before the node the relationship is declared in. Primarily used as a base type for other relationship types.
The cloudify.relationships.depends_on relationship type is for use as a logical representation of dependencies between nodes. You should only use it in very specific cases when the other two relationship types are not relevant, or when you want to specify that a certain node should be created before or after another for the sake of ordering.
The cloudify.relationships.contained_in Relationship Type
Derived from cloudify.relationships.depends_on. In addition to the order of evaluation provided by the base type, it implies the containment of one node inside another. This has a couple of consequences:
- Only one “contained in” relationship can be declared per node in a blueprint. This limitation is enforced universally by the DSL parser ( i.e. it isn’t a workflow specific quality ).
- If the target node of the relationship derives from cloudify.nodes.Compute, the contained node lifecycle will be executed remotely on the target.
Example:
node_templates:
host:
type: cloudify.nodes.Compute
interfaces:
. . . .
web_server:
type: cloudify.nodes.WebServer
interfaces:
. . . .
relationships:
type: cloudify.relationships.contained_in
target: host
Some detail is omitted, but the net result is that the web_server node is remotely installed on the host node.
Note that the implementation of cloudify.relationships.contained_in does not necessarily dictate that a node must be physically contained in another node. Physical containment is only implied if the target of the relationship derives from cloudify.nodes.Compute. For instance, consider an ip node that is contained in a network node. Although the IP isn’t actually contained within the network itself, the semantics of a contained_in relationship will be enforced (i.e. only one such relationships permitted, and the evaluation of the ip node happens after the network node is. Any logic that actually associates the IP with the network is generally provided by the IP type implementation.
It is important to realize that some plugins may assign additional meaning to the basic relationships, while others will declare new relationship types to make the meaning more explicit. Always make sure to understand how each node type you use interprets relationships.
Semantics of Multiple Node Instances
At runtime, all blueprint nodes become node instances, each created by the node template in the blueprint. By default, each blueprint node results in a single instance, but multiple instances can be configured for each node. For the contained_in relationship, if the source node has X instances, then each instance of the target node will have X instance of the source node in it (installed in it if it’s a compute node).
Example:
node_templates:
host:
type: cloudify.nodes.Compute
capabilities:
scalable:
properties:
default_instances: 2
interfaces:
. . . .
web_server:
type: cloudify.nodes.WebServer
interfaces:
. . . .
capabilities:
scalable:
properties:
default_instances: 4
relationships:
type: cloudify.relationships.contained_in
target: host
In the example, four web_server instances will be installed on each of two host instances.
The cloudify.relationships.connected_to Relationship Type
Derived from cloudify.relationships.depends_on. It adds some configurability to the base relationship type, but otherwise has the same semantics. A node can have any number of connected_to relationships to other nodes, all of which will precede it during the install lifecycle phase (and conversely follow it during the uninstall lifecycle phase).
Example:
node_templates:
application:
type: web_app
relationships:
- type: cloudify.relationships.connected_to
target: database
database:
type: database
In the above example, an application node is connected to a database node. The net effect is that the database will be instantiated before the application node.
Semantics of Multiple Node Instances
The connection_type property in the cloudify.relationships.connected_to relationship allows you to connect a node to an arbitrary instance of another node. You cannot specify a specific instance.
Example:
node_templates:
application:
type: web_app
capabilities:
scalable:
properties:
default_instances: 2
relationships:
- type: cloudify.relationships.connected_to
target: database
properties:
connection_type: all_to_one
database:
type: database
capabilities:
scalable:
properties:
default_instances: 2
In the above example there are two application node instances that connect to a randomly selected database node instance.
The default configuration for connection_type is all_to_all. In an all_to_all configuration, each instance of web_app would connect to both instances of database.
The cloudify.relationships.depends_on_lifecycle_operation Relationship Type
As an extension of cloudify.relationships.depends_on relationship type, when a node depends on another node but could start creation earlier in the lifecycle operations of that node (precreate, create, configure, start),
this is relevant in case that the requirements of the node are met earlier in the creation process. For example application service node that uses a DB service which only needs it’s connection url, so when this url is
available, probably after the create lifecycle operation, the application service node could start creation and to wait for the DB node to fully finish.
Notice, that a node could only depend on a defined lifecycle operation, due to that only an operation could generate outputs for it’s users.
Usage example:
node_templates:
application:
type: web_app
capabilities:
scalable:
properties:
default_instances: 2
relationships:
- type: cloudify.relationships.depends_on_lifecycle_operation
target: database
properties:
operation: create
database:
type: database
capabilities:
scalable:
properties:
default_instances: 2SharedResource Related Relationship Types
In a multi-service architecture application, the scenario of a shared resource (for example: shared DB service, filesystem, etc) is a common one. And in some cases there are dependencies to them by other application’s nodes, so in order to enforce those relationships is required or/and if a custom connection is needed (the custom connection will allow running a workflow on the shared resource, for example creating logs directory for each node in the deployment on a shared filesystem). The following relationships are for supporting these use cases.
The shared resource scenario is supported by the SharedResource node type, for further information please visit SharedResource.
The cloudify.relationships.depends_on_shared_resource Relationship Type
As an extension of cloudify.relationships.depends_on relationship type, this can only target a node of
SharedResource type. This relationship will allow running any workflow (custom or not) ,which is defined
in the target node’s deployment, as a part from establish and unlink relationship lifecycle operations.
Also if the SharedResource node has been created with different Cloudify client connection, those settings
will be taken from the node properties if exists else it will use default Cloudify client.
Relationship settings:
- Properties that can be set for establish and unlink relationship lifecycle:
inputs:workflow_id: The workflow id that will be run in the SharedResource’s deployment as implementation defined there.parameters: Optional, inputs for running the workflow in the format of key-value dictionary.timeout: Timeout in seconds for running the specified workflow on the deployment with a default of 10 seconds.
Simple example
node_templates:
shared_resource_node:
type: cloudify.nodes.SharedResource
properties:
resource_config:
deployment:
id: shared_resource_deployment
app:
type: cloudify.nodes.WebServer
relationships:
- type: cloudify.relationships.depends_on_shared_resource
target: shared_resource_node
target_interfaces:
cloudify.interfaces.relationship_lifecycle:
establish:
inputs:
workflow_id: custom_workflow
parameters: {input: 'x'}
unlink:
inputs:
workflow_id: un_custom_workflow
timeout: 15The cloudify.relationships.connected_to_shared_resource Relationship Type
As an extension of cloudify.relationships.connected_to relationship type, this can only target a node of
type of SharedResource. This relationship will allow running any workflow (custom or not) ,which is defined
in the target node’s deployment, as a part from establish and unlink relationship lifecycle.
With support for scaling the relationship according to cloudify.relationships.connected_to features.
Also if the SharedResource node has been created with different Cloudify client connection, those settings
will be taken from the node properties if exists else it will use default Cloudify client.
Relationship settings:
- Properties that can be set for establish and unlink relationship lifecycle:
inputs:workflow_id: The workflow id that will be run in the SharedResource’s deployment as implementation defined there.parameters: Optional, inputs for running the workflow in the format of key-value dictionary.timeout: Timeout in seconds for running the specified workflow on the deployment with a default of 10 seconds.
Simple example
node_templates:
shared_resource_node:
type: cloudify.nodes.SharedResource
properties:
resource_config:
deployment:
id: shared_resource_deployment
app:
type: cloudify.nodes.WebServer
relationships:
- type: cloudify.relationships.connected_to_shared_resource:
target: shared_resource_node
target_interfaces:
cloudify.interfaces.relationship_lifecycle:
establish:
inputs:
workflow_id: custom_workflow
parameters: {input: 'x'}
unlink:
inputs:
workflow_id: un_custom_workflow
timeout: 15connection_type: all_to_all and all_to_one
As mentioned previously, the relationship types cloudify.relationships.connected_to and cloudify.relationships.depends_on and those that derive from it have a property named connection_type for which the value can be either all_to_all or all_to_one (The default value is all_to_all).
The following diagrams make their semantics clearer.
all_to_all
Consider the following blueprint:
node_templates:
application:
type: web_app
capabilities:
scalable:
properties:
default_instances: 2
relationships:
- type: cloudify.relationships.connected_to
target: database
properties:
connection_type: all_to_all
database:
type: database
capabilities:
scalable:
properties:
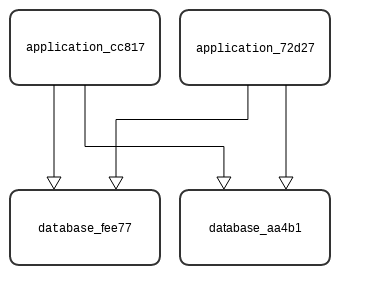
default_instances: 2When deployed, there are two node instances of the application node and two node instances of the database node. All application node instances are connected to all database node instances. This would have relevance in the case of two Node.js application servers that must connect to two memcached nodes, for example.
all_to_one
Consider the following blueprint:
node_templates:
application:
type: web_app
capabilities:
scalable:
properties:
default_instances: 2
relationships:
- type: cloudify.relationships.connected_to
target: database
properties:
connection_type: all_to_one
database:
type: database
capabilities:
scalable:
properties:
default_instances: 2When deployed, there are two node instances of the application node and two node instances of the database node. All application node instances are connected to one database node instance (selected at random). This would have relevance in the case of two Node.js application servers that must add themselves as users on a single Cassandra node, for example.
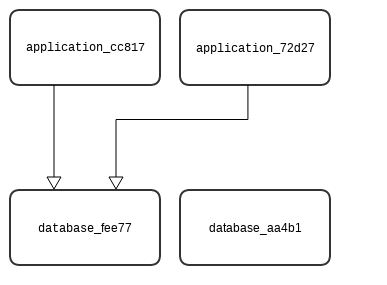
Relationship Instances
In the case in which you have a node with two instances and two relationships configured for them, when a deployment is created, the node instances are instantiated in the model. In the same way that node instances are instantiated for each node, relationship instances are instantiated for each relationship.
Declaring Relationship Types
You can declare your own relationship types in the relationships section in the blueprint. This is useful when you want to change the default implementation of how nodes interact.
Relationship Type Declaration
Declaring relationship types is done as follows:
relationships:
relationship1:
derived_from: ""
source_interfaces: {}
target_interfaces: {}
properties:
connection_type: ""
relationship2: {}
...Relationship Type Schema
| Keyname | Required | Type | Description |
|---|---|---|---|
| derived_from | no | string | The relationship type from which the new relationship is derived. |
| source_interfaces | no | dict | A dictionary of interfaces. |
| target_interfaces | no | dict | A dictionary of interfaces. |
| connection_type | no | string | Valid values: all_to_all and all_to_one |
Relationship Type Example
relationships:
app_connected_to_db:
derived_from: cloudify.relationships.connected_to
source_interfaces:
cloudify.interfaces.relationship_lifecycle:
postconfigure:
implementation: scripts/configure_my_connection.py
node_templates:
application:
type: web_app
capabilities:
scalable:
properties:
default_instances: 2
relationships:
- type: cloudify.relationships.contained_in
target: vm
- type: app_connected_to_db
target: databaseIn the above example, a relationship type called app_connected_to_db is created that inherits from the base cloudify.relationships.connected_to relationship type and implements a specific configuration (by running scripts/configure_my_connection.py) for the type.
Relationship Interfaces
Each relationship type (and instance) has source_interfaces and target_interfaces.
For a specific node:
source_interfacesdefines interfaces of operations that are executed on the node in which the relationship is declared.target_interfacesdefines interfaces of operations that are executed on the node that its relationship targets.
Defining interfaces source_interfaces and target_interfaces does not necessarily mean that their operations will be executed. That is, operations defined in cloudify.interfaces.relationship_lifecycle will be executed when running install/uninstall workflows. You can also add a custom relationship interface and write a custom workflow to execute operations from the new interface.
Example:
relationships:
source_connected_to_target:
derived_from: cloudify.relationships.connected_to
source_interfaces:
cloudify.interfaces.relationship_lifecycle:
postconfigure:
implementation: scripts/configure_source_node.py
target_interfaces:
cloudify.interfaces.relationship_lifecycle:
postconfigure:
implementation: scripts/configure_target_node.py
node_templates:
source_node:
type: app
relationships:
- type: source_connected_to_target
target: target_nodeIn the above example, the postconfigure lifecycle operation in the source_connected_to_target relationship type is configured once in its source_interfaces section and in the target_interfaces section. This means that the configure_source_node.py script will be executed on host instances of source_node and the configure_target_node.py will be executed on host instances of target_node. (This assumes that the plugin executor is configured as host_agent and not central_deployment_agent. Otherwise, source_interfaces operations and target_interfaces operations are all executed on the Manager.)
How Relationships Affect Node Creation
Declaring relationships affects the node creation/teardown flow in respect to the install/uninstall workflows respectively.
When declaring a relationship and using the built in install workflow, the first lifecycle operation of the source node is executed after the entire set of lifecycle operations of the target node are executed and completed.
When using the uninstall workflow, the opposite is true.
For instance, in the example, all source operations (node_instance operations, source_interfaces relationships operations and target_interfaces relationship operations) for source_node are executed after all target_node operations are completed. This removes any uncertainties about whether a node is ready to have another node connect to it or be contained in it, due to it not being available. Of course, it’s up to you to define what “ready” means.
Relationships Extensions
For building your application’s blueprints in a layered architecture, building blocks approach, the ability to wire in different component’s relationships is very useful and allows good separation of your application to self dependent blocks. Which can allow creating a complex inter-service relationships and full application view.
Example:
- Cloud provider vm basic blueprint
imports:
- http://www.getcloudify.org/spec/cloudify/5.0.0/types.yaml
inputs:
server_ip:
description: >
The ip of the server the application will be deployed on.
agent_user:
description: >
User name used when SSH-ing into the started machine.
agent_private_key_path:
description: >
Path to a private key that resides on the management machine.
SSH-ing into agent machines will be done with this key.
node_templates:
vm:
type: cloudify.nodes.Compute
properties:
ip: { get_input: server_ip }
agent_config:
user: { get_input: agent_user }
key: { get_input: agent_private_key_path }- Micro service blueprint
imports:
- http://www.getcloudify.org/spec/cloudify/5.0.0/types.yaml
inputs:
webserver_port:
description: >
The HTTP web server port.
default: 8080
node_templates:
http_web_server:
type: cloudify.nodes.WebServer
properties:
port: { get_input: webserver_port }
relationships:
- type: cloudify.relationships.contained_in
target: vm
interfaces:
cloudify.interfaces.lifecycle:
configure: scripts/configure.sh
start: scripts/start.sh
stop: scripts/stop.sh- Full application blueprint
imports:
- cloud_infrastructure--blueprint:vm
- service--blueprint:http_service
node_templates:
service--http_web_server:
relationships:
- type: cloudify.relationships.contained_in
target: cloud_infrastructure--vmFor more information about service composition please check out in depth look.