Built-in Workflows
Overview
Cloudify comes with a number of built-in workflows, covering:
- Application installation / uninstallation (
install/uninstall) - Application start / stop / restart (
start/stop/restart) - Scaling (
scale) - Healing (
heal) - Running arbitrary operations (
execute_operation)
Built-in workflows are declared and mapped in types.yaml, which is usually imported either directly or indirectly via other imports.
# Snippet from types.yaml
workflows:
install: default_workflows.cloudify.plugins.workflows.install
uninstall: default_workflows.cloudify.plugins.workflows.uninstall
execute_operation:
mapping: default_workflows.cloudify.plugins.workflows.execute_operation
parameters:
operation: {}
operation_kwargs:
default: {}
run_by_dependency_order:
default: false
type_names:
default: []
node_ids:
default: []
node_instance_ids:
default: []The implementations for these workflows can be found at cloudify-plugins-common.
Built-in workflows are not special in any way - they use the same API and framework as any custom workflow is able to use, and one may replace them with different workflows with the same names.
The Install Workflow
Workflow name: install
Workflow description: Workflow for installing applications.
Workflow high-level pseudo-code:
For each node, for each node instance (in parallel):
- Wait for node instance relationships to be started. (Only start processing this node instance when the node instances it depends on are started).
- Execute
cloudify.interfaces.validation.createoperation. 1 - Execute
cloudify.interfaces.lifecycle.precreateoperation. 1 - Execute
cloudify.interfaces.lifecycle.createoperation. 1 - Execute
cloudify.interfaces.relationship_lifecycle.preconfigurerelationship operations.2 - Execute
cloudify.interfaces.lifecycle.configureoperation.1 - Execute
cloudify.interfaces.relationship_lifecycle.postconfigurerelationship operations.2 - Execute
cloudify.interfaces.lifecycle.startoperation.1 - If the node instance is a host node (its type is a subtype of
cloudify.nodes.Compute):- Install agent workers and required plugins on this host.
- Execute
cloudify.interfaces.monitoring_agentinterfaceinstallandstartoperations. 1
- Execute
cloudify.interfaces.lifecycle.poststartoperation. 1 - Execute
cloudify.interfaces.monitoring.startoperation. 1 - Execute
cloudify.interfaces.relationship_lifecycle.establishrelationship operations.2
The Uninstall Workflow
Workflow name: uninstall
Workflow description: Workflow for uninstalling applications.
Workflow parameters:
ignore_failure: Iftrue, then operation errors encountered during uninstallation will not prevent the workflow from moving on; errors will be logged and printed. Iffalse, errors encountered during uninstallation will prompt the orchestrator to behave similarly toinstall(that is: retrying recoverable errors, aboring on non-recoverable errors).
Workflow high-level pseudo-code:
For each node, for each node instance (in parallel):
- Wait for dependent node instances to be deleted. (Only start processing this node instance when the node instances dependent on it are deleted).
- Execute
cloudify.interfaces.validation.deleteoperation. 1 - Execute
cloudify.interfaces.monitoring.stopoperation. 1 - Execute
cloudify.interfaces.lifecycle.prestopoperation. 1 - If node instance is host node (its type is a subtype of
cloudify.nodes.Compute):- Execute
cloudify.interfaces.monitoring_agentinterfacestopanduninstalloperations. 1 - Stop and uninstall agent workers.
- Execute
- Execute
cloudify.interfaces.lifecycle.stopoperation.1 - Execute
cloudify.interfaces.relationship_lifecycle.unlinkrelationship operations.2 - Execute
cloudify.interfaces.lifecycle.deleteoperation.1 - Execute
cloudify.interfaces.lifecycle.postdeleteoperation.1
The Execute Operation Workflow
Workflow name: execute_operation
Workflow description: Generic workflow for executing arbitrary operations on nodes.
Workflow parameters:
operation: The name of the operation to execute (Mandatory).operation_kwargs: A dictionary of keyword arguments that will be passed to the operation invocation (Default:{}).allow_kwargs_override: A boolean describing whether overriding operations inputs defined in the blueprint by using inputs of the same name in theoperation_kwargsparameter is allowed or not (Default:null[means that the default behavior, as defined by the workflows infrastructure, will be used]).run_by_dependency_order: A boolean describing whether the operation should execute on the relevant nodes according to the order of their relationships dependencies or rather execute on all relevant nodes in parallel (Default:false).type_names: A list of type names. The operation will be executed only on node instances which are of these types or of types which (recursively) derive from them. An empty list means no filtering will take place and all type names are valid (Default:[]).node_ids: A list of node ids. The operation will be executed only on node instances which are instances of these nodes. An empty list means no filtering will take place and all nodes are valid (Default:[]).node_instance_ids: A list of node instance ids. The operation will be executed only on the node instances specified. An empty list means no filtering will take place and all node instances are valid (Default:[]).
<div class="panel panel-primary panel-warning">
<div class="panel-heading">Warning</div>
<div class="panel-body">
Executing an operation on a node which has that interface operation but has not mapped it to any concrete implementation will simply do nothing. However, attempting to execute an operation on a node which doesn’t have the relevant interface operation will result in a workflow execution error. Use the filtering fields to ensure the operation is only executed on nodes which the operation might be relevant to.
Workflow high-level psuedo-code:
For each node, for each node instance:
- Filter out instances whose node is not in the
node_idslist (unless its empty). - Filter out instances whose id is not in the
node_instance_idslist (unless its empty). - Filter out instances whose node type is not in or a descendant of a type which is in the
type_nameslist (unless its empty).
If run_by_dependency_order is set to true:
create a task dependency between the following section’s (1) task for a given instance and the (3) task for all instances it depends on.1
For each of the remaining node instances:
- Send a node instance event about starting the execution operation.
- Execute the
operationoperation for the instance, with theoperation_kwargspassed to the operation invocation. - Send a node instance event about completing the execution of the operation.
The Start Workflow
Workflow name: start
Workflow description: Can be used to start all, or a subset of, node templates.
This workflow is a wrapper for the execute_operation workflow, allowing the user to easily start
the topology (or a subset thereof). Calling the start workflow is equivalent to calling execute_operation
while passing cloudify.interfaces.lifecycle.start as the operation name.
Workflow parameters:
operation_parms: Passed as-is to theoperation_kwargsparameter ofexecute_operation. Defaults to an empty dict.run_by_dependency_order: Similar semantics to the identically-named parameter of theexecute_operationworkflow. Defaults toTrue.type_names: Passed as-is to thetype_namesparameter ofexecute_operation. Defaults to an empty list.node_ids: Passed as-is to thenode_idsparameter ofexecute_operation. Defaults to an empty list.node_instance_ids: Passed as-is to thenode_instance_idsparameter ofexecute_operation. Defaults to an empty list.
The Stop Workflow
Workflow name: stop
Workflow description: Can be used to stop all, or a subset of, node templates.
This workflow is a wrapper for the execute_operation workflow, allowing the user to easily stop
the topology (or a subset thereof). Calling the stop workflow is equivalent to calling execute_operation
while passing cloudify.interfaces.lifecycle.stop as the operation name.
Workflow parameters:
See workflow parameters for the start workflow above.
The Restart Workflow
Workflow name: restart
Workflow description: Can be used to restart all, or a subset of, node templates.
This workflow simply calls the stop workflow, followed by start.
Workflow parameters:
stop_parms: Passed as-is to theoperation_parmsparameter ofstop. Defaults to an empty dict.start_parms: Passed as-is to theoperation_parmsparameter ofstart. Defaults to an empty dict.run_by_dependency_order: See description of this parameter in thestartworkflow above.type_names: See description of this parameter in thestartworkflow above.node_ids: See description of this parameter in thestartworkflow above.node_instance_ids: See description of this parameter in thestartworkflow above.
NOTE: The restart workflow performs all stop operations first, and then performs all start operations.
The Heal Workflow
Workflow name: heal
Workflow description: Reinstalls the whole subgraph of the system topology by applying the uninstall and install workflows’ logic respectively. The subgraph consists of all the node instances that are contained in the compute node instance which contains the failing node instance and/or the compute node instance itself. Additionally, this workflow handles unlinking and establishing all affected relationships in an appropriate order.
Workflow parameters:
node_instance_id: The ID of the failing node instance that needs healing. The whole compute node instance containing (or being) this node instance will be reinstalled.
Workflow high-level pseudo-code:
-
Retrieve the compute node instance of the failed node instance.
-
Construct a compute sub-graph (see note below).
-
Uninstall the sub-graph:
- Execute uninstall lifecycle operations (
stop,delete) on the compute node instance and all it’s contained node instances. (1) - Execute uninstall relationship lifecycle operations (
unlink) for all affected relationships.
- Execute uninstall lifecycle operations (
-
Install the sub-graph:
- Execute install lifecycle operations (
create,configure,start) on the compute node instance and all it’s contained nodes instances. - Execute install relationship lifecycle operations (
preconfigure,postconfigure,establish) for all affected relationships.
- Execute install lifecycle operations (
A compute sub-graph can be thought of as a blueprint that defines only nodes that are contained inside a compute node. For example, if the full blueprint looks something like this:
...
node_templates:
webserver_host:
type: cloudify.nodes.Compute
relationships:
- target: floating_ip
type: cloudify.relationships.connected_to
webserver:
type: cloudify.nodes.WebServer
relationships:
- target: webserver_host
type: cloudify.relationships.contained_in
war:
type: cloudify.nodes.ApplicationModule
relationships:
- target: webserver
type: cloudify.relationships.contained_in
- target: database
type: cloudify.relationships.connected_to
database_host:
type: cloudify.nodes.Compute
database:
type: cloudify.nodes.Database
relationships:
- target: database_host
type: cloudify.relationships.contained_in
floating_ip:
type: cloudify.nodes.VirtualIP
...Then the corresponding graph will look like so:
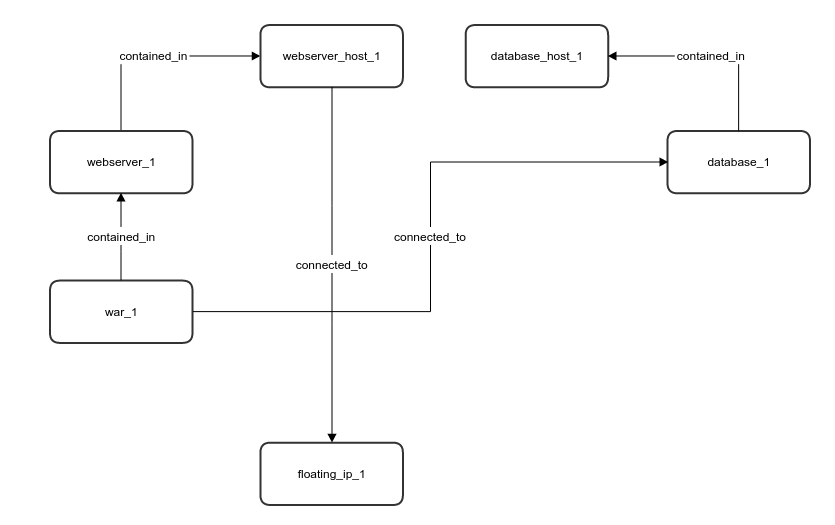
And a compute sub-graph for the webserver_host will look like:
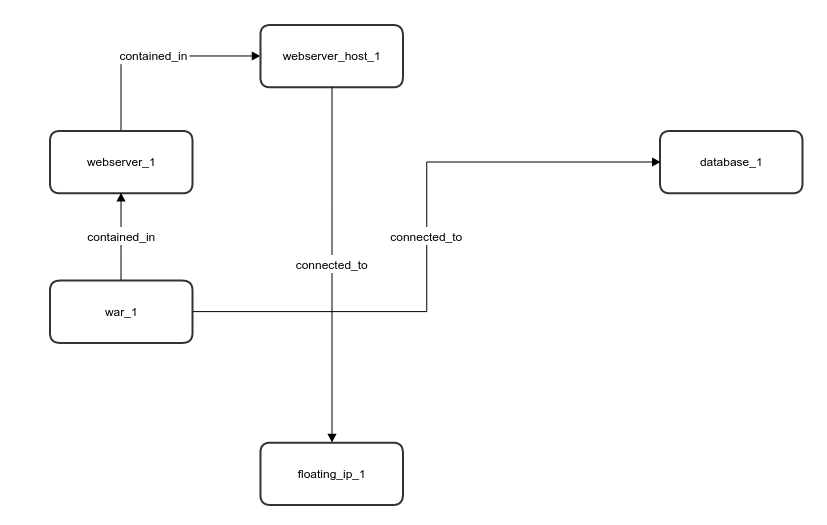
This sub-graph determines the operations that will be executed during the workflow execution. In this example:
- The following node instances will be re-installed:
war_1,webserver_1andwebserver_host_1. - The following relationships will be re-established:
war_1connected todatabase_1andwebserver_host_1connected tofloating_ip_1.
The Scale Workflow
Workflow name: scale
Workflow description:
Scales out/in the node subgraph of the system topology applying the install/uninstall workflows’ logic respectively.
If the entity denoted by scalable_entity_name is a node template that is contained in a compute node (or is a compute node itself) and scale_compute is true,
the node graph will consist of all nodes that are contained in the compute node which contains scalable_entity_name and the compute node itself.
Otherwise, the subgraph will consist of all nodes that are contained in the node/scaling group denoted by scalable_entity_name.
In addition, nodes that are connected to nodes that are part of the contained subgraph will have their establish relationship operations executed during scale out
and their unlink relationship operations executed during scale in.
Workflow parameters:
scalable_entity_name: The name of the node/scaling group to apply the scaling logic to.delta: The scale factor. (Default:1)- For
delta > 0: If the current number of instances isN, scale out toN + delta. - For
delta < 0: If the current number of instances isN, scale in toN - |delta|. - For
delta == 0, leave things as they are.
- For
scale_compute: shouldscaleapply on the compute node containing the node denoted byscalable_entity_name. (Default:false)- If
scalable_entity_namespecifies a node, andscale_computeis set tofalse, the subgraph will consist of all the nodes that are contained in the that node and the node itself. - If
scalable_entity_namespecifies a node, andscale_computeis set totrue, the subgraph will consist of all nodes that are contained in the compute node that contains the node denoted byscalable_entity_nameand the compute node itself. - If the node denoted by
scalable_entity_nameis not contained in a compute node or it specifies a group name, this parameter is ignored.
- If
include_instances: An instance or list of instances to prioritize for scaling down.- This inclusion will only apply for the operation on which it is specified, it will not be saved as a preference.
- This cannot be set while scaling up or while
scale_computeistrue. - The instance or instances must exist.
- If the negative
deltais lower than the number of listed instances, then the remaining instances will be selected arbitrarily. - If the negative
deltais higher than the number of listed instances then not all of the listed instances will be removed.
exclude_instances: An instance or list of instances to avoid when scaling down.- This exclusion will only apply for the operation on which it is specified, it will not be saved as a preference.
- This cannot be set while scaling up or while
scale_computeistrue. - The instance or instances must exist.
- If the amount of nodes remaining would be equal to or less than the number of excluded nodes, the operation will abort.
- If an instance is also in the
include_instanceslist, the operation will abort. - Note that when using scaling groups, specified node instances may belong to different group instances. If too many group instances are excluded, the operation will abort.
Workflow high-level pseudo-code:
- Retrieve the scaled node/scaling group, based on
scalable_entity_nameandscale_computeparameters. - Start deployment modification, adding or removing node instances and relationship instances.
- If
delta > 0:- Execute install lifecycle operations (
create,configure,start) on added node instances. - Execute the
establishrelationship lifecycle operation for all affected relationships.
- Execute install lifecycle operations (
- If
delta < 0:- Execute the
unlinkrelationship lifecycle operation for all affected relationships. - Execute uninstall lifecycle operations (
stop,delete) on removed node instances.
- Execute the
The Install New Agents Workflow
Workflow name: install_new_agents
Workflow description:
Installs agents on all VMs related to a particular deployment and connects them to the Cloudify Manager’s RabbitMQ instance. Please note that the old Manager has to be running during the execution of this workflow. What is worth mentioning as well is that the old agents don’t get uninstalled. This workflow’s common use case is executing it after having successfully restored a snapshot on a new Manager in order for the Manager to gain control over applications that have been orchestrated by the previous Manager.
Workflow parameters:
install_agent_timeout: The timeout for a single agent installation (Default:300s).node_ids: A list of node ids. The new agent will be installed only on node instances that are instances of these nodes. An empty list means no filtering will take place and all nodes will be taken under consideration (Default:[]).node_instance_ids: A list of node instance ids. The new agent will be installed only on the node instances specified. An empty list means no filtering will take place and all node instances will be taken under consideration (Default:[]).